How to Structure Test Cases for Maximum Reusability

Meta description: Learn proven techniques for structuring reusable test cases that reduce maintenance effort, improve coverage consistency, and scale across projects and teams.

Quick Answer
Reusable test cases follow a modular structure: atomic steps, parameterized inputs, abstracted preconditions, and clear separation between test logic and test data. By designing each test case as a self-contained, composable unit, teams eliminate redundant authoring, reduce maintenance overhead, and maintain consistent coverage as the product evolves.
Key Takeaways
- Modular decomposition — breaking test cases into atomic, single-purpose steps — is the foundation of reusability across projects and releases.
- Separating test data from test logic allows the same structured test case to validate dozens of scenarios without duplication.
- Standardized naming conventions and tagging taxonomies make reusable test cases discoverable, which is the prerequisite for actual reuse.
TL;DR
Poorly structured test cases cost engineering organizations significant time through duplication, inconsistent coverage, and high maintenance burden. This article presents a systematic framework for designing test cases that can be reused across sprints, projects, and teams. It covers structural patterns, data parameterization strategies, naming standards, and organizational practices that make reusability practical rather than theoretical.
Introduction
A QA team ships 1,200 test cases for a product release. Six months later, a new module launches and the team writes 900 more — despite 40% of the logic overlapping with existing cases. The original cases were written to pass a specific sprint's acceptance criteria, not to serve as reusable assets.
This pattern repeats across the industry. Test cases are treated as disposable artifacts tied to a single story or release, rather than as durable components of a testing library. The result is a growing repository of near-duplicate cases that diverge over time, producing inconsistent coverage and escalating maintenance costs.
The fix is structural. Reusability is not a feature added after the fact — it is a design property baked into how each test case is authored from the start.
What Is a Reusable Test Case?
A reusable test case is one that can be executed — without modification — across multiple contexts: different releases, different modules, different environments, or different data sets. It achieves this through three structural properties:
- Atomicity — it validates exactly one behavior or condition.
- Parameterization — it accepts variable inputs without requiring edits to the case itself.
- Independence — it carries no implicit dependencies on other test cases, specific data states, or execution order.
A test case that says "Log in with user admin/password123 and verify the dashboard loads" is not reusable. A test case that says "Log in with [valid credentials] and verify [landing page] loads within [threshold] seconds" is reusable — because the bracketed parameters can be supplied per execution context.
Why Reusability Matters at Scale
The cost of non-reusable test cases compounds with organizational growth. Below is an illustrative estimate of how duplication scales across team sizes.
Estimated Impact of Test Case Duplication by Team Size
| Dimension | Small Team (3-5 QAs) | Mid-Size Team (10-20 QAs) | Enterprise Team (50+ QAs) |
| Active test cases | 500 - 2,000 | 5,000 - 15,000 | 30,000 - 100,000+ |
| Estimated duplication rate | 15 - 25% | 25 - 40% | 35 - 55% |
| Hours spent per quarter on duplicate maintenance | 40 - 80 | 200 - 500 | 1,000 - 3,000 |
| Avg. time to locate an existing reusable case | 5 - 10 min | 15 - 30 min | 30 - 60+ min |
(All figures are illustrative estimates based on industry patterns.)
The maintenance hours alone justify investment in structured reusability. But the hidden cost is inconsistency — when duplicated test cases diverge, the same feature gets validated differently by different teams, producing unreliable quality signals.
How to Structure Test Cases for Reuse
The following framework addresses the five structural layers of a reusable test case.
Layer 1: Atomic Step Design
Each step in a test case should perform exactly one user action or one system verification. Compound steps ("Enter username, enter password, and click Submit") resist reuse because they bundle actions that may need to be tested independently.
Non-reusable step structure:
| Step | Action | Expected Result |
| 1 | Enter credentials and submit the login form | User is redirected to the dashboard |
Reusable step structure:
| Step | Action | Expected Result |
| 1 | Enter [username] into the username field | Username field displays the entered value |
| 2 | Enter [password] into the password field | Password field masks the entered value |
| 3 | Click the Submit button | System processes the authentication request |
| 4 | Verify the landing page | [Landing page] loads within [threshold] seconds |
The atomic version allows steps 1-3 to be reused in any authentication-related test case, while step 4 can be reused in any page-load verification scenario.
Layer 2: Parameterization Strategy
Parameterization separates test logic from test data. The case structure remains constant; only the input values change per execution.
Three levels of parameterization:
| Level | Scope | Example |
| Field-level | Individual input values | [username], [password], [expected_status] |
| Environment-level | Infrastructure variables | [base_url], [api_version], [timeout_ms] |
| Scenario-level | Business context variations | [user_role], [subscription_tier], [locale] |
A well-parameterized test case can validate a login flow for an admin user on staging, a free-tier user on production, and a localized user on a regional environment — all from a single case definition.
Layer 3: Precondition Abstraction
Preconditions define the required system state before execution. Reusable test cases reference precondition templates rather than inline setup instructions.
| Approach | Example | Reusability |
| Inline precondition | "Create a user with email test@example.com and role Admin" | Low — tied to specific data |
| Abstracted precondition | "Precondition: [Active user] with [role] exists in [environment]" | High — parameterized and linkable |
| Shared precondition module | "Apply precondition module: USER_ACTIVE_WITH_ROLE" | Highest — centrally maintained |
Shared precondition modules act as reusable setup routines. When the user creation flow changes, updating the module propagates the fix to every test case that references it.
Layer 4: Naming and Tagging Taxonomy
Reusable test cases that cannot be found will not be reused. A consistent naming convention and tagging system makes the test library searchable.
Recommended naming pattern:
[Module]_[Feature]_[Scenario]_[Variation]
Examples:
Auth_Login_ValidCredentials_StandardUserAuth_Login_InvalidCredentials_LockedAccountCheckout_Payment_SuccessfulCharge_CreditCard
Recommended tagging dimensions:
| Tag Category | Example Values |
| Module | Auth, Checkout, Profile, Reporting |
| Priority | P0-Critical, P1-High, P2-Medium, P3-Low |
| Test Type | Functional, Regression, Smoke, Integration |
| Reusability Scope | Global, Module-specific, Project-specific |
| Data Dependency | Parameterized, Static, Environment-bound |
Tags enable filtered searches. A QA engineer starting work on a new checkout feature can query for all Module:Checkout + Reusability:Global + Type:Regression cases and immediately identify what already exists before writing new cases.
Layer 5: Version Control and Traceability
Reusable test cases evolve. Without version control, a case modified for one project may break its validity in another context. Each reusable test case should maintain:
- A version identifier tied to the product version it validates.
- A change log documenting what was modified and why.
- Traceability links to requirements or user stories, so impact analysis is possible when requirements change.
Distribution of QA Effort: Current State vs. Reusability-Optimized
The following table represents illustrative estimates of how QA teams allocate effort, comparing organizations with ad-hoc test case practices against those with structured reusability programs.
QA Effort Allocation (Pie Chart Data)
| Activity | Ad-Hoc Practice (% of effort) | Reusability-Optimized (% of effort) |
| Writing new test cases | 35% | 20% |
| Maintaining existing cases | 25% | 10% |
| Searching for existing cases | 15% | 5% |
| Executing tests | 15% | 40% |
| Test analysis and reporting | 10% | 25% |
(All figures are illustrative estimates.)
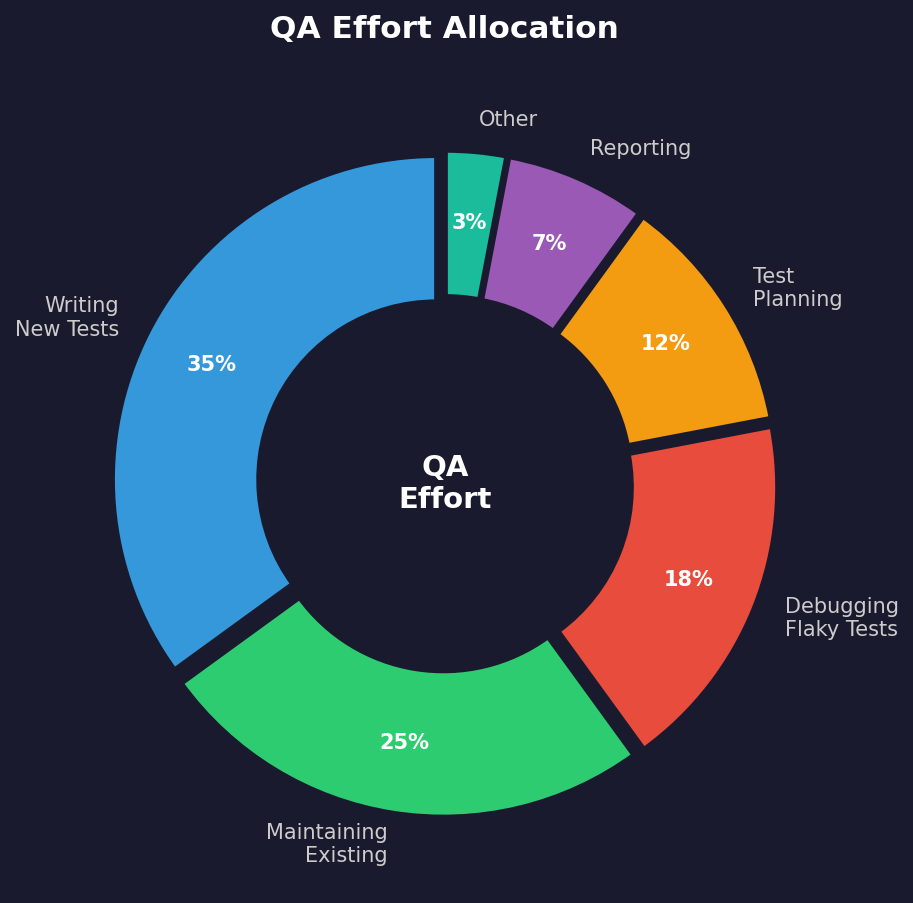
The shift is significant. Teams with structured reusability spend less time on authoring and maintenance, and redirect that effort toward execution and analysis — the activities that directly produce quality insights.
Expert Analysis
Structuring test cases for reusability is fundamentally a design discipline, not a tooling problem. Organizations that attempt to retrofit reusability onto an existing unstructured test library typically achieve marginal results. The cases were authored with implicit assumptions — hardcoded data, environment-specific steps, compound actions — that resist modular decomposition after the fact.
The more effective approach is to establish structural standards before the first case is written. This means defining the parameterization scheme, the naming convention, the tagging taxonomy, and the precondition module library as part of the test strategy — not as an afterthought.
A common objection is that structured authoring takes longer upfront. This is true for individual cases. An atomic, parameterized, properly tagged test case takes roughly 30-50% more time to author than a quick, inline case (illustrative estimate). But the break-even point arrives quickly. Once a reusable case prevents even two instances of duplication, it has paid for the initial investment. At enterprise scale — where test libraries grow into tens of thousands of cases — the compounding returns are substantial.
The organizational prerequisite is discoverability. Modern test management platforms address this through structured repositories with search, filtering, and linking capabilities. But even with basic tooling, a disciplined naming convention and tagging taxonomy can make a test library navigable enough to support reuse.
The key insight is that reusability is a property of structure, not intention. A team can intend for their cases to be reusable, but unless the structure enforces atomicity, parameterization, and independence, reuse will not happen in practice.
FAQ
Q1: Should every test case be designed for reusability?
No. Context-specific test cases — such as one-time exploratory validations or highly specialized edge-case scenarios — do not benefit from the overhead of full parameterization and modular design. A practical rule: if a test case is likely to be executed in more than one sprint or by more than one team member, design it for reuse.
Q2: How do I measure the reusability rate of my test library?
Track two metrics: the reuse ratio (number of times a case is referenced across test plans divided by total cases) and the duplication rate (percentage of cases with greater than 80% step overlap with another case). A healthy library shows a rising reuse ratio and a declining duplication rate over time.
Q3: Does reusability conflict with agile test case practices?
It does not. Agile emphasizes working software and minimal waste. Reusable test cases reduce waste by eliminating redundant authoring. The key is to integrate structural standards into the team's definition of done for test cases, rather than treating reusability as a separate initiative.
Q4: How do I handle test cases that are almost reusable but need slight variations?
Use a parent-child or template-instance model. The parent case defines the reusable structure with parameters. Each variation is an instance that supplies specific parameter values. This preserves the single-source structure while accommodating scenario-specific differences.
Q5: What is the biggest barrier to test case reusability in practice?
Discoverability. Even well-structured reusable cases go unused if team members cannot find them. Consistent naming conventions, a searchable tag taxonomy, and regular library audits are more important than any specific authoring technique.
Actionable Recommendations
Audit your existing test library for duplication. Identify cases with greater than 80% step overlap. These are candidates for consolidation into parameterized, reusable cases.
Define a naming convention before writing new cases. Adopt the
[Module]_[Feature]_[Scenario]_[Variation]pattern or a similar structured format. Document it in your test strategy and enforce it through peer review.Create a precondition module library. Extract the 10-15 most common setup routines (user creation, data seeding, environment configuration) into shared modules referenced by test cases rather than duplicated within them.
Implement a tagging taxonomy with a "Reusability Scope" dimension. Tag every case as Global, Module-specific, or Project-specific. Use this tag to filter candidates before authoring new cases.
Establish a quarterly library review cadence. Identify stale cases, merge duplicates, update parameterization schemes, and retire cases that no longer map to active requirements.
Measure and report reuse metrics. Track the reuse ratio and duplication rate at the team and project level. Make these metrics visible in sprint retrospectives to sustain organizational attention on reusability.
Conclusion
Test case reusability is not achieved through good intentions or better tooling alone. It is achieved through deliberate structural design: atomic steps, parameterized inputs, abstracted preconditions, disciplined naming, and systematic tagging. These practices require upfront investment but deliver compounding returns as the test library, the product, and the team grow.
The organizations that treat test cases as durable, composable assets — rather than disposable sprint artifacts — build testing libraries that scale. Those that do not face an ever-expanding maintenance burden that consumes the time and attention their teams need for meaningful quality work.
Start with structure. Reuse follows.
About the Author
Naina Garg is an AI-Driven SDET at TestKase, where she focuses on scalable test architecture and intelligent test management practices. She writes about test design patterns, automation strategy, and quality engineering fundamentals for enterprise teams.



